










After finishing my postgraduate entrance exams, I set up an MC server to play with my friends. I hadn't researched it before, and I didn't realize how much there was to tinker with in an MC server. Just configuring various plugins was exhausting. So, after returning home for the holidays, I decided to use an LLM framework to import the plugin wikis into a knowledge base and let AI help me write the configurations.
Initially, I used maxkb, but there were two main issues: first, the community edition had limitations and kept prompting me, which was annoying. Second, for some reason (possibly due to my settings), no matter how I tweaked it, the AI's responses were always very short in token length and had almost no memory (even though I had modified it).
Yesterday, I tried installing dify, but dify's web crawler only supports Jina Reader and Firecrawl, both of which are paid services (they offer free tokens, but you can also self-deploy). During my research, I came across crawl4ai, an open-source project. This project can quickly crawl and generate Markdown documents suitable for LLM knowledge bases, and it can even use LLM models to help analyze webpage structure data. After using it myself, I found it to be a very fast and convenient crawler framework. I'm writing this blog not only to save the code I used but also to recommend it to everyone.
First, let's take a look at the official introduction from GitHub:
- Built for LLMs: Creates smart, concise Markdown optimized for RAG and fine-tuning applications.
- Lightning Fast: Delivers results 6x faster with real-time, cost-efficient performance.
- Flexible Browser Control: Offers session management, proxies, and custom hooks for seamless data access.
- Heuristic Intelligence: Uses advanced algorithms for efficient extraction, reducing reliance on costly models.
- Open Source & Deployable: Fully open-source with no API keys—ready for Docker and cloud integration.
- Thriving Community: Actively maintained by a vibrant community and the #1 trending GitHub repository.
Github: unclecode/crawl4ai: 🚀🤖 Crawl4AI: Open-source LLM Friendly Web Crawler & Scraper
Official Documentation: Home - Crawl4AI Documentation
Single Page Crawling
My use of crawl4ai is mainly based on modifying the code from the official documentation (their documentation is really great). For single-page crawling, I'll just paste the official code without further explanation.
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
# Create an instance of AsyncWebCrawler
async with AsyncWebCrawler() as crawler:
# Run the crawler on a URL
result = await crawler.arun(url="https://crawl4ai.com")
# Print the extracted content
print(result.markdown)
# Run the async main function
asyncio.run(main())Multi-Page Crawling
Session Reuse for Multi-Page Crawling
The most headache-inducing part for me was crawling multiple pages of plugin wikis. crawl4ai solved this problem very well.
I relied on the wiki's sitemap to get the list of URLs. Most wikis/websites have a sitemap.
The official documentation provides high-performance multi-page crawling code, which doesn't open a new browser for each page but instead opens multiple pages in a single browser. This not only saves resources but also speeds up the process. Below is my code, which is mostly copied from the official documentation, with the addition of a method to parse the sitemap and get the URL list.
import asyncio
from typing import List
from urllib.parse import urlparse
from xml.etree import ElementTree
import requests
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig
from crawl4ai.markdown_generation_strategy import DefaultMarkdownGenerator
async def crawl_sequential(urls: List[str]):
print("\n=== Sequential Crawling with Session Reuse ===")
browser_config = BrowserConfig(
headless=True,
# For better performance in Docker or low-memory environments:
extra_args=["--disable-gpu", "--disable-dev-shm-usage", "--no-sandbox"],
)
crawl_config = CrawlerRunConfig(
markdown_generator=DefaultMarkdownGenerator()
)
# Create the crawler (opens the browser)
crawler = AsyncWebCrawler(config=browser_config)
await crawler.start()
try:
session_id = "session1" # Reuse the same session across all URLs
for index,url in enumerate (urls):
result = await crawler.arun(
url=url,
config=crawl_config,
session_id=session_id
)
if result.success:
print(f"Successfully crawled: {url}")
print(f"Markdown length: {len(result.markdown_v2.raw_markdown)}")
with open(f"./result/{urlparse(url).path.replace('/','_')}.md", "w",encoding='utf-8') as f:
f.write(result.markdown_v2.raw_markdown)
else:
print(f"Failed: {url} - Error: {result.error_message}")
finally:
# After all URLs are done, close the crawler (and the browser)
await crawler.close()
def get_pydantic_ai_docs_urls():
"""
Fetches all URLs from the Pydantic AI documentation.
Uses the sitemap (https://ai.pydantic.dev/sitemap.xml) to get these URLs.
Returns:
List[str]: List of URLs
"""
sitemap_url = "https://example.com/sitemap.xml"
try:
response = requests.get(sitemap_url)
response.raise_for_status()
# Parse the XML
root = ElementTree.fromstring(response.content)
# Extract all URLs from the sitemap
# The namespace is usually defined in the root element
namespace = {'ns': 'http://www.sitemaps.org/schemas/sitemap/0.9'}
urls = [loc.text for loc in root.findall('.//ns:loc', namespace)]
return urls
except Exception as e:
print(f"Error fetching sitemap: {e}")
return []
async def main():
urls = get_pydantic_ai_docs_urls()
await crawl_sequential(urls)
if __name__ == "__main__":
asyncio.run(main())Parallel Crawling
crawl4ai can also crawl multiple pages simultaneously, which significantly speeds up the process when extracting many pages. The code is again from the official documentation, with the addition of the sitemap parsing method. After crawling, it outputs a list of failed URLs and automatically saves the successfully crawled pages to the specified directory in Markdown format (the naming method is my own and can be modified as needed).
import os
import sys
from urllib.parse import urlparse
from xml.etree import ElementTree
import psutil
import asyncio
__location__ = os.path.dirname(os.path.abspath(__file__))
__output__ = os.path.join(__location__, "output")
import requests
# Append parent directory to system path
parent_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(parent_dir)
from typing import List
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
dirname: str = "dirname"
sitemapurl: str ="https://example.com/sitemap.xml"
crawl_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
css_selector="div.content"
)
async def crawl_parallel(urls: List[str], max_concurrent: int = 3):
print("\n=== Parallel Crawling with Browser Reuse + Memory Check ===")
# We'll keep track of peak memory usage across all tasks
peak_memory = 0
process = psutil.Process(os.getpid())
def log_memory(prefix: str = ""):
nonlocal peak_memory
current_mem = process.memory_info().rss # in bytes
if current_mem > peak_memory:
peak_memory = current_mem
print(f"{prefix} Current Memory: {current_mem // (1024 * 1024)} MB, Peak: {peak_memory // (1024 * 1024)} MB")
# Minimal browser config
browser_config = BrowserConfig(
headless=True,
verbose=False, # corrected from 'verbos=False'
extra_args=["--disable-gpu", "--disable-dev-shm-usage", "--no-sandbox"],
)
# Create the crawler instance
crawler = AsyncWebCrawler(config=browser_config)
await crawler.start()
try:
# We'll chunk the URLs in batches of 'max_concurrent'
success_count = 0
fail_count = 0
fail_urls = []
for i in range(0, len(urls), max_concurrent):
batch = urls[i : i + max_concurrent]
tasks = []
for j, url in enumerate(batch):
# Unique session_id per concurrent sub-task
session_id = f"parallel_session_{i + j}"
task = crawler.arun(url=url, config=crawl_config, session_id=session_id)
tasks.append(task)
# Check memory usage prior to launching tasks
log_memory(prefix=f"Before batch {i//max_concurrent + 1}: ")
# Gather results
results = await asyncio.gather(*tasks, return_exceptions=True)
# Check memory usage after tasks complete
log_memory(prefix=f"After batch {i//max_concurrent + 1}: ")
# Evaluate results
for url, result in zip(batch, results):
if isinstance(result, Exception):
print(f"Error crawling {url}: {result}")
fail_count += 1
elif result.success:
with open(f"./{dirname}/{urlparse(url).path.replace('/', '_')}.md", "w", encoding='utf-8') as f:
f.write(result.markdown_v2.raw_markdown)
success_count += 1
else:
fail_urls.append(url)
fail_count += 1
print(f"\nSummary:")
print(f" - Successfully crawled: {success_count}")
print(f" - Failed: {fail_count}")
print(f" - Failed URLs: {fail_urls}")
finally:
print("\nClosing crawler...")
await crawler.close()
# Final memory log
log_memory(prefix="Final: ")
print(f"\nPeak memory usage (MB): {peak_memory // (1024 * 1024)}")
def get_pydantic_ai_docs_urls():
"""
Fetches all URLs from the Pydantic AI documentation.
Uses the sitemap (https://ai.pydantic.dev/sitemap.xml) to get these URLs.
Returns:
List[str]: List of URLs
"""
#sitemap_url = "https://itemsadder.devs.beer/chinese/sitemap.xml"
sitemap_url = sitemapurl
try:
response = requests.get(sitemap_url)
response.raise_for_status()
# Parse the XML
root = ElementTree.fromstring(response.content)
# Extract all URLs from the sitemap
# The namespace is usually defined in the root element
namespace = {'ns': 'http://www.sitemaps.org/schemas/sitemap/0.9'}
urls = [loc.text for loc in root.findall('.//ns:loc', namespace)]
return urls
except Exception as e:
print(f"Error fetching sitemap: {e}")
return []
async def main():
urls = get_pydantic_ai_docs_urls()
await crawl_parallel(urls, max_concurrent=10)
if __name__ == "__main__":
asyncio.run(main())Some Tips
crawl_config
My usage is just scratching the surface. crawl4ai has many more powerful features. For example, in the code above, I set up crawl_config to use a CSS selector to specify the part of the page to crawl. This allows me to remove the header and list sections that are present on every wiki page. crawl_config also has many exclusion settings that can help you quickly remove specified DOM elements. There are also cache settings, and more. Please refer to the documentation for more details.
Before setting: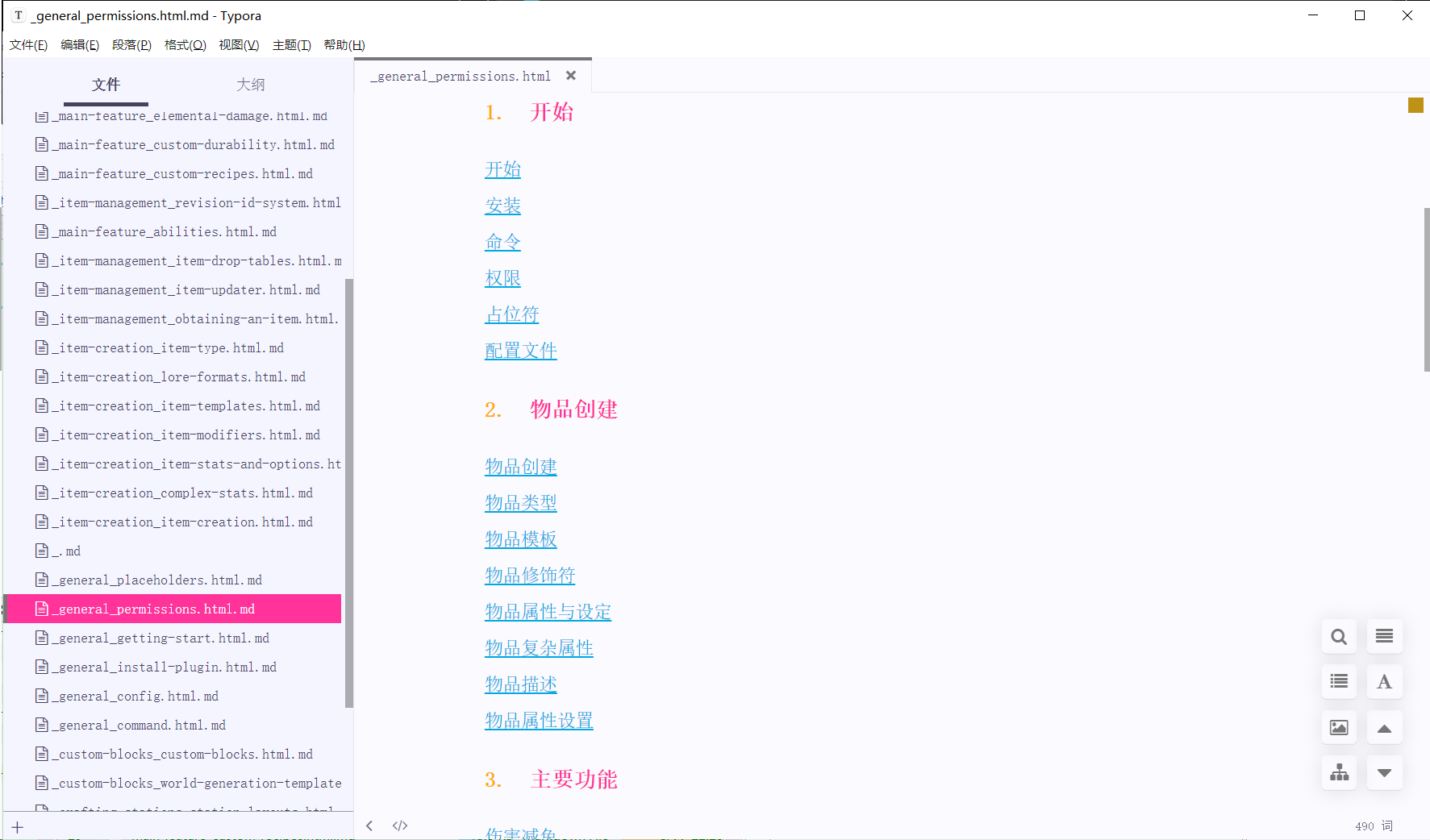
After setting: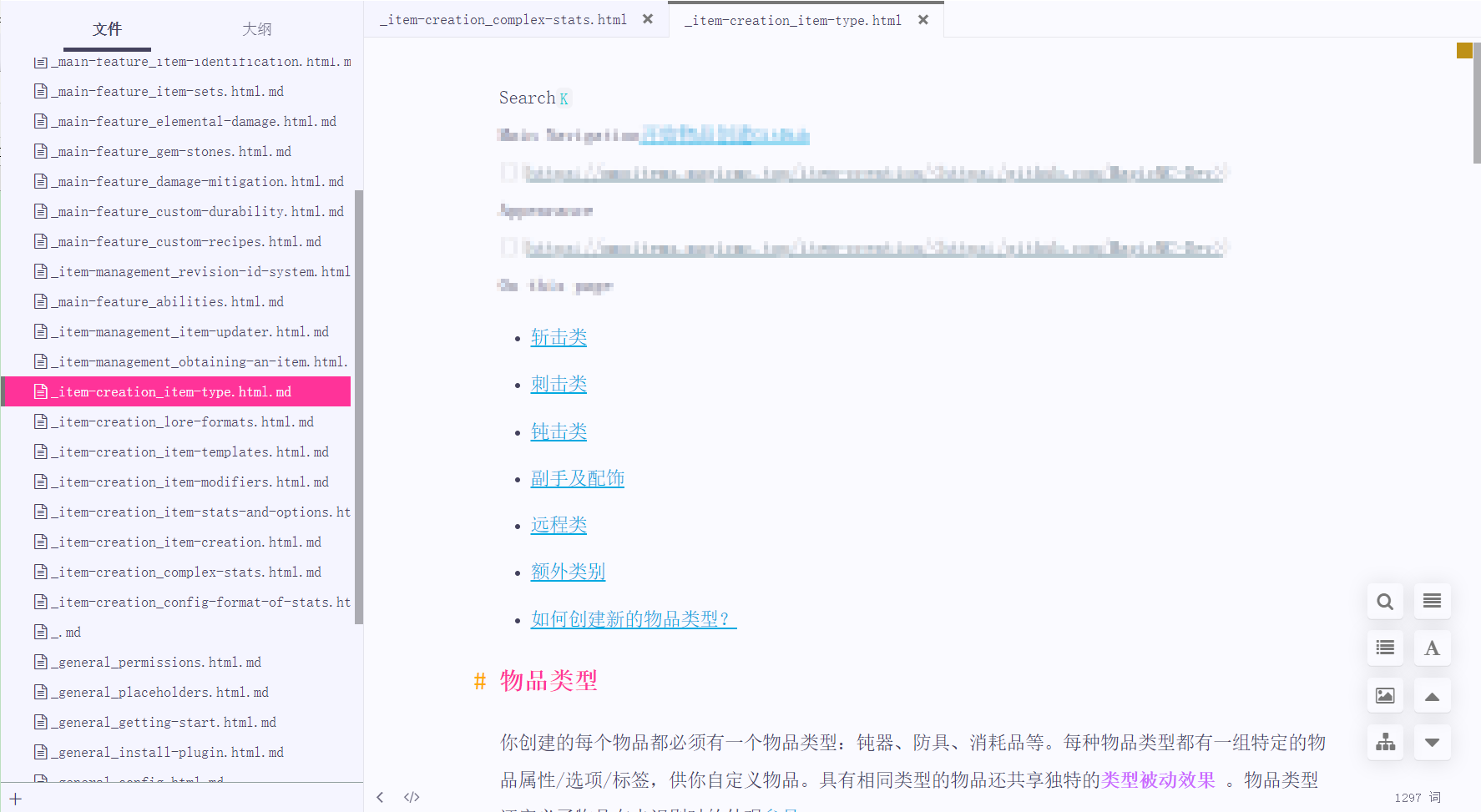
Extracting JSON
crawl4ai supports using JSON to define the data structure for crawling, specifying DOM elements as specific elements. This not only eliminates the need for LLM but also provides greater stability. It works very well when crawling highly structured web pages.
More
As you can see, my current use case doesn't yet involve LLM assistance because I only need to crawl the content of the wiki. So, for more advanced features, you'll need to check the documentation and learn on your own.
In my experience, it's really powerful, with great speed and performance, perfectly fitting my needs. I believe crawl4ai can be used in almost any scenario, not just for crawling databases.

Comments | NOTHING